

Where It All Began
I started my journey into the amazing world of Amazon FBA back in 2014. Alongside researching niches, factories, importing laws, creating a brand, and launching a product on Amazon (what many of us have all gone through), I was also recruited to help build what would become ZonBlast, the foremost product launch platform at the time.
In my capacity at ZonBlast, my days were filled with running product launches and tracking performance. It was my job to figure out the most effective ways to get a product listing on page one of Amazon for its most competitive keywords.
Literally all day every day I launched, tracked, assessed, researched, tested, ideated strategies, and repeated. There were very few others who had their finger on the pulse of the A9 algorithm like me back then.
One of my first observations, first with my own products, then with many ZonBlast clients’, was an odd dip in keyword rank at exactly the six-month mark. Meaning, after selling live on the Amazon platform for six months, product listings would drop two or three spots in rank (from very consistent positions beforehand) for their most relevant and competitive terms.
This was obviously an incredibly important phenomenon to study. In my research and brainstorming with ZonBlast’s CEO, we stumbled on an interesting concept. We were discussing technical analysis in stock trading. Specifically, when we starting talking about moving averages (an average of stock price open/close/median prices over a period of time) an idea occurred to me…
What if part of Amazon’s ranking algorithm was a moving average of sales? Moving averages are often calculated over benchmark periods of time; daily, weekly, monthly, 180 days, yearly, etc. If this were the case, then that would mean that newer products would not have a 180 day calculation factoring in their averages yet.
SO, after 180 days, all the good and bad days averaged together, would result in a slightly less magnificent performance, leading to a slight dip in ranking. That would mean, if after six months a product listing was performing at it’s true base, then the previous period would, in essence, be a honeymoon period.
This was where the first concepts of a honeymoon period were born.
Back End Search Term Shake-Up
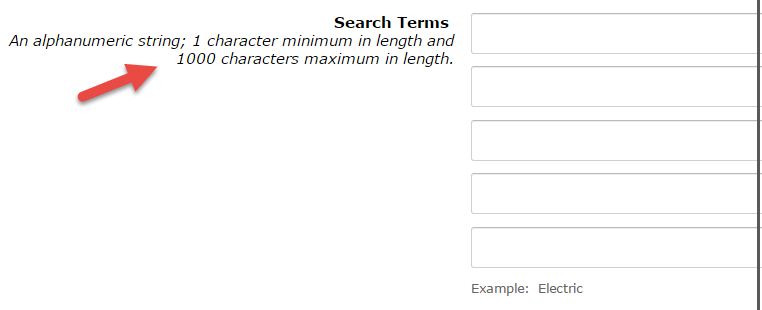
There used to be five rows that each held up to 1000 characters for search terms
I think it was around 2016 when the first major algorithm shake-up happened. It was an interesting time because EVERYONE was focused on launches and the algorithm through the lens of how Amazon would react to incentivized reviews. And while they did make changes to the TOS, the algorithm didn’t shift until they made changes to back-end search terms.
First, Amazon massively expanded the back-end search term area, allowing for thousands of characters (five kw rows each up to 1000 characters in length). Then, after a few months, they massively shrank it to only a few bytes (250 total today). They’ve gone back and forth over the years but it was that first update where we started to see things change.
See, the back-end search term modifications was an attempt to evolve the search algorithm to prioritizing relevance. Before then, relevance was pretty much determined primarily by sales popularity (with some instances where things like clicks, add-to-carts, or other actions boosted relevance).
When Amazon started working on back-end search terms, it was because they wanted to change how indexing happened, and how relevance was scored. Back-end search terms allowed for data to be incorporated into relevance that was beyond just the title and other front-end detail page elements.
From our end, this shift in focus to relevance changed how launches worked too. In the beginning days of launching, doing a single day of massive sales (facilitated by a large discount coupon) would do the trick. However, after relevance started changing, the single day blowout was no longer as effective.
That’s when we had to evolve our own launch strategies and came up with an evenly spaced drip of discounted sales over a period of days.
And as Amazon’s relevance engine continued to be refined, our launch strategies had to as well. The most effective method went from an evenly spaced out promotion over four days to steadily increasing sales over seven days, and then to staggering the sales every other day for two weeks.
We also saw a shift from sales velocity being the biggest factor in keyword rank to conversion rates to a number of other levers. Needless to say, running product launches showed us that there were definitely changes happening under the hood at Amazon almost monthly. And we had front-row seats to it all.

(Get the Ultimate Guide to ChatGPT for Amazon Sellers Here ==> signalytics.ai/chatgpt)
Is It a Can Opener or a Bottle Opener?

One of the biggest breakthroughs in my understanding of how Amazon was refining its relevance engine came in 2018 when I was selling a 5-in-1 bottle opener, can opener, jar opener, etc all in one device.
I was working on ranking for my biggest keyword – “can opener” when I noticed that no matter what I did I simply could not rank for “bottle opener.” After exhausting all of my ranking strategies I finally reached out to Amazon seller central to discuss the issue with them. I thought surely this must mean something was wrong in the unseen parts of my listing.
That’s when, after a decently long back-and-forth with a support agent, I discovered what was happening. As it turned out, my category-item-keyword (the keyword that matched my product to a specific subcategory) was ‘can opener’ and not ‘bottle opener.’ My listing was not permitted to hold both, and the subcategory actually dictated what keywords a product could rank for.
Wait…what?
Yes, this was when I learned that category actually controlled what your listing could have relevance for, and therefore what keywords it could rank for.
At the time, this was a huge insight. Almost none of us sellers had any idea the levers that Amazon pulled behind the curtain that would curtail our ranking efforts.
This put a huge emphasis on correct category placement. It also explained random significant rank drops people were seeing due to being forced into different categories without their knowledge.
The Second Honeymoon Period
As we continued running product launches, we noticed the six month rank drop pattern dissolve. It would appear the shift toward relevance factors also meant that those sales benchmarks were no longer as important.
Even still, we noticed a period of time where “ranking was super easy.” Meaning, in the life of a listing, there was a period right after the creation of that listing where it took less units and less time to achieve targeted rank results.
Testing and researching lead me to determine that there was a second type of honeymoon period. This type, predicated on a window where relevance was granted due to lack of data.
This was later recognized by other industry experts as a cold-start period, and confirmed somewhat in Daria Sorokino’s Joy of Ranking Products paper.
The logic explaining this basically stated that, when a listing is new Amazon’s algorithm doesn’t know quite yet what keywords it is truly relevant for, mainly because customer behavior actions haven’t occurred yet. As such, the “benefit of the doubt” for all the keywords indexed is given. That would mean that all of the front and back-end keywords are considered fully relevant during this period, and high sales through a launch would lend to easier ranking.
Regardless of whether this could be substantiated through the science literature, this was what many who oversaw launches observed. Which is why the concept of the honeymoon period persisted.
Ranking World Rattled by Machine Learning
In 2016 a machine learning engineer working with Amazon published a paper along with a few colleagues called “The Joy of Ranking Products.” Even though it was published in 2016, Daria did not go on to explain what the paper meant until she gave a presentation on it that was later published to YouTube in 2017.
Despite the science being “exposed” years ago, it wasn’t until Seller Sessions’ Danny McMillan stumbled across it in 2020/2021 that the Amazon seller community at large became aware of it. He graciously shared his findings and many of us went to work to dissect it.
In Daria’s live presentation she addresses the “cold-start problem” where she discusses a period of 24 hours to as much as seven days where new listings may lack relevant customer behavior to accurately assess relevance.
Proponents of the honeymoon period latched onto this explanation as the necessary evidence that explains the phenomenon we were all witnessing.
Amazon Seeks Human Intervention To Check ML Activities

It was around the time of our discussing the Joy of Ranking Products’ findings that I made a discovery of my own. Somewhat randomly, by luck of the timing and Google’s search algorithm, I came to find a job posting on the task-outsourcing site Toloka, owned by Russian Yandex.
Toloka is similar to services like Amazon Mechanical Turk where people crowdsource minor online actions; look at this website and answer questions, search for this product and click on this one, vote this review up, etc etc.
The job posting was for a task that was published by Amazon. In it, Amazon was asking for people to conduct a series of searches on their website and then record instances of specific behaviors.
Presumably this was to check behind the work of their algorithm to ensure it was acting as programmed.
I clicked on the job and agreed to take the competency test (they had workers perform the actions in a test to ensure they understood what was being asked of them). This test revealed some very interesting things about how Amazon defined relevance.
I won’t go into detail about the Toloka findings here, but you can read at length about it here.
But I will share what I discovered. Amazon was sorting results from any given search on its home page into one of four categories:
- Exact
- Substitute
- Complement
- Irrelevant
Each category had its own definition, outlined by Amazon. But the implications were clear. Here we had, essentially four internal tags that Amazon’s algorithm was sorting results with to determine relevance level.
Fascinating stuff!
Ok, that’s enough of my personal story. Now let’s look at A9’s evolution through the lens of the science literature.
Evolution of the A9 According to the Literature

(Get the Ultimate Guide to ChatGPT for Amazon Sellers Here ==> signalytics.ai/chatgpt)
The Joy of Ranking Products
The ‘Joy of Ranking‘ paper is a foundational work that lays the groundwork for understanding Amazon’s A9 search algorithm. Authored by Daria Sorokina, the paper provides valuable insights into the complex mechanisms that determine how products are ranked in Amazon’s search results.
Its importance lies in its attempt to demystify the often opaque logic behind Amazon’s ranking algorithm, offering a scientific basis for what many sellers and marketers have tried to decode through trial and error.
Key Features Like Ranking Functions and Customer Behavior Analytics
The A9 algorithm as described in the ‘Joy of Ranking‘ employs a variety of ranking functions that consider both textual relevance and customer behavior. The algorithm uses these functions in tandem with country-specific indices to deliver search results tailored to different markets.
Another intriguing aspect is the incorporation of customer behavior analytics, which considers metrics like click-through rates and purchase history to refine rankings. This multi-faceted approach ensures that the search results are not just relevant but also aligned with what customers are actually interested in.
Interesting to note, however, is the technology employed at this stage in Amazon’s building of its relevance engine. Sorokina’s work primarily used a general machine learning framework for ranking within categories, Natural Language Processing (NLP) techniques for matching queries and products, and algorithms targeted at unique tasks of specific categories. These models used only query-independent features, and most of the score was precalculated offline by humans.
That was probably a lot of technical gobbledegook for many (myself included). But it’s important when discussing the evolution of the technology to be aware of what technology was used. So, at this stage it was; NLP + query-independent features + offline calculated scoring. Also, the sorting method at this stage was “pairwise ranking” (that’ll be important later).
Multi-Objective Relevance Ranking
The Multi-Dimensional approach to Relevance was introduced as an advancement on this technology in 2019. This was a more nuanced approach to assigning relevance and sorting rank. This methodology went beyond simple textual relevance to consider multiple dimensions, including more in-depth customer behavior, product attributes, and even business constraints like inventory levels.
Take note, this advancement injected business constraints into the relevance engine. This was the moment when geo-location began to truly impact ranking.
The Augmented Lagrangian Method for Optimization

To solve the complexity arising from balancing multiple objectives, Multi-Objective Relevance Ranking employs a mathematical technique known as the Augmented Lagrangian Method. This method allows the algorithm to effectively optimize multiple conflicting objectives simultaneously, ensuring that the final search results are a well-rounded representation of what is both relevant and practical.
In layman terms, this means the methods and models employed by Sorokina have changed and therefore the A9 algorithm is not what it was in 2016 when the Joy of Ranking Products was released to the world.
Amazon’s Use of Human-Operated Confirmations
Amazon also employs human-operated confirmations, a discovery made evident by the micro-worker tasks assigned for manual labeling of product listings. These tasks serve as a mechanism for gathering human feedback on the relevance and appropriateness of search results.
The human-generated labels could potentially serve as “ground truth” data for training Amazon’s machine learning models. By incorporating this human element, Amazon can fine-tune its algorithms to better align with human perceptions of relevance, thereby making the search results more user-friendly and accurate.
The Next Evolution: BERT & Listwise Pairing
New publications have surfaced shining a light on what the future of the A9 algorithm holds. Now, it’s important to note that just because a paper is published doesn’t mean we’ll see these changes adopted completely.
Amazon has a tendency to test small batches for effectiveness first, and if things don’t work out, will move on. That said, given the way they’ve improved the algorithm over the last 7+ years, it is incredibly likely this is the direction the technology will take.
Amazon Implements LLMs
BERT, or Bidirectional Encoder Representations from Transformers, represents a significant leap in the field of Natural Language Processing (NLP). It’s designed to better understand the context and semantics of language, making it exceptionally good at understanding the nuances of human queries. This is made possible through its bidirectional training, which allows it to consider the entire context of a word by looking at the words that come before and after it.
BERT could theoretically improve upon Amazon’s existing search algorithm in a number of ways. The potential application of BERT in Amazon’s search algorithm could be groundbreaking.
Its ability to understand context could lead to a more nuanced interpretation of user queries. This would complement the Multi-Objective Relevance strategy tremendously. Furthermore, BERT’s unique ability to understand natural language queries would lead to a better user experience.
BERT can also adapt to new language trends, slang, or idiomatic expressions without manual updates. This could be beneficial, especially in a global market with diverse linguistic attributes.
What Does This Mean?
The best way to illustrate how BERT could improve upon the current A9 Algorithm is by explaining what would no longer be needed, thus illustrating how BERT would improve efficiency.
What would no longer be needed:
- Hand-Tuning: The manual effort to fine-tune ranking functions could be significantly reduced, if not eliminated.
- Static Keyword Lists: With BERT’s natural language understanding capabilities, static lists for keyword-based indexing could become obsolete.
- Separate Models for Different Regions: A well-trained BERT model could handle queries from different regions, reducing the need for country-specific indices and ranking algorithms.
Listwise Pairs and Transformers
![]()
Listwise Learning-to-Rank, as exemplified by the RankFormer paper, takes a holistic approach to ranking search results. Unlike traditional methods that evaluate items in isolation or in pairs, listwise ranking evaluates the entire list of potential results to determine their collective relevance.
What it does:
It employs ‘listwise labels,’ which are aggregated sets of features or metrics that capture the collective relevance of a list of items, rather than evaluating them individually.
By considering the entire list of items, RankFormer minimizes the noise associated with individual rankings, leading to more stable and reliable search results. This is especially valuable in complex ecosystems like Amazon, where multiple factors influence product rankings.
The role of transformers:
Enhanced Semantic Understanding
The advent of transformer models adds a layer of semantic depth to the listwise ranking approach. These models are adept at understanding contextual relationships between words, thereby making listwise ranking even more nuanced and effective.
Improvement in Absolute Utility
Beyond relative rankings, transformer models can also evaluate the ‘absolute utility’ of each listed item. This means not just ranking items relative to each other but also assessing how useful each item is on its own merit.
Synergies Between BERT and Listwise Ranking
The intersection of BERT and Listwise Ranking in Amazon’s search algorithm could represent a seismic shift in how products are ranked and displayed. Here’s a more detailed look at how these two cutting-edge technologies could work together to create a more effective, context-aware search algorithm.
Complementary Strengths
BERT’s Strengths: BERT excels at understanding the nuances of language, offering a deep understanding of the context in which words and phrases are used.
Listwise Ranking’s Strengths: On the other hand, Listwise Ranking provides a holistic approach that considers the entire list of products, using aggregated metrics to determine their collective relevance.
Sequential Application for Greater Accuracy
One conceivable application could be a two-stage ranking process:
Initial Relevance Determination: In the first stage, BERT could be used to analyze the semantic relevance of each product listing to the search query. This would provide an initial sorting of products based on how well they match the user’s intent.
Refinement via Listwise Ranking: The second stage could employ Listwise Ranking to further refine these initial rankings. By considering the list as a whole, the algorithm can better account for relational factors like how products complement each other or how they fit into broader customer needs and behaviors.
Example: Smart Home Products
Imagine a user searching for “smart home products.” BERT could first identify listings that not only contain the keywords but also are contextually related to the concept of smart homes. Listwise Ranking could then evaluate these products collectively, considering factors like customer ratings, relevance to current smart home trends, and compatibility with other smart home products. The end result would be a list that is not only relevant but also highly contextual and useful for the user.
Enhanced User Experience
The ultimate benefit of this synergy would be an enhanced user experience. Customers would find products that are not only relevant to their queries but also to their broader goals and lifestyles. This could lead to higher customer satisfaction, increased sales, and potentially higher lifetime customer value.
Quick Recap So Far
We went over my personal experience, from the perspective of someone running a product launch service. I shared how algorithm shifts impacted product ranking through the eyes of a seller.
Then we discussed the scientific research and the highly technical aspects of the Amazon relevance engine and ranking algorithm. We saw the evolution of the technology from NLP models, that Daria Sorokina helped develop, which did algorithmic magic based on human-developed standards, to Augmented Lagrangian methods, which included things like stock levels and warehouse location in the relevance calculations.
Then we talked about the future of Amazon’s algorithm as it adopts more efficient machine learning methods paired with artificial intelligence.
Now the question is…what can YOU do with this information?
What This Will Mean for Sellers and Their Software Tools?

(Get the Ultimate Guide to ChatGPT for Amazon Sellers Here ==> signalytics.ai/chatgpt)
What Sellers Should Do
As Amazon’s search algorithm grows increasingly sophisticated, sellers will need to adapt their strategies to stay competitive. Here are some recommendations:
Focus on Semantic Relevance: Given the introduction of BERT and its capabilities, sellers should optimize their listings to be semantically relevant to potential queries. This goes beyond simple keyword stuffing and includes providing comprehensive, context-rich product descriptions.
This will put even more emphasis on robust descriptions, because the LLM will have better context if the product’s use cases, example situations, and customer intentions are well described.
Understand the Full Product Ecosystem: With the listwise approach in play, it’s crucial for sellers to understand not only how their product ranks but also how it fits into the broader ecosystem of products that appear in search results.
This has many implications, including back-end keyword usage, complementary product choices, and even product pairings/bundles. By considering the entire ecosystem, sellers start to understand the niche, and therefore where their product fits in it, better. This understanding will help sellers make better category decisions and help them to defend against competitors more competently.
Keep an Eye on Business Metrics: Given the multi-objective relevance model that considers business constraints like stock levels, sellers should regularly monitor and adjust these metrics to maintain high rankings.
This isn’t new. We’ve been doing this for awhile. But, we can assume that once BERT is adopted the A.I. will have some sensitivity to the business metrics (as those will need to be fed from an outside source…BERT does not handle that natively). This will mean that even newer sellers will need to have supply chain planning pinned down and tight right from launch.
Basically, how this all differs slightly from what we sellers have been doing for some time now is, we’ll need to start taking a more holistic approach to our products and listing optimization. We’ll need to consider more inputs than before; competitor adjacent products, adjacent markets, overall layout and feel, stock levels, mental associations, etc.
It will require more work. It will require more focus, attention, and discipline. But, nobody said selling on Amazon has been getting easier.
What Software Should Do
The next thing to consider is what the software services we have come to know and love should do to adapt. These shifts have always impacted ranking, tracking, analytics and keyword software. The evolution to A.I. will only do so more rapidly.
The new complexities introduced by BERT and listwise ranking necessitate a more nuanced approach from third-party Amazon seller tools. Here are some avenues for evolution:
Provide More Nuanced Insights: With the algorithm considering multiple factors for ranking, third-party tools should offer more intricate analyses that go beyond simple keyword tracking.
For example, incorporating semantic analysis. Given BERT’s focus on context, third-party tools could benefit from incorporating semantic analysis into their feature set. Advanced NLP techniques could be employed to analyze the semantic relevance of product listings, offering suggestions for optimization based on context rather than mere keyword presence.
Real-Time Monitoring: A.I. algorithms could offer real-time monitoring of multiple factors affecting product rankings, providing instant insights to sellers. This could include stock levels and geo-rank, but also competitor rank movement and category changes.
By tracking these things is real-time, sellers would have the ability to pivot or adapt quickly to changes just as they are happening.
Predictive Analytics: Machine learning models could be developed to predict future ranking trends based on current and historical data, enabling sellers to preemptively adjust their strategies.
The same concepts could also be employed to predict future product trends, to better predict future stock levels, and give insights to future adspend. The sky is the limit when using A.I. for business prediction.
Conclusion and Predictions
Back in 2014, the single most important thing that a seller could do was have a highly optimized listing. And I don’t mean optimized the way we do it now. I mean GREAT copywriting, that spoke only to the potential customer. And AWESOME product photography.
Why?
Because back then Amazon didn’t have this sophisticated relevance machine it has now. So what determined relevance, and therefore what determined rank, was popularity.
That means conversion rate and sales were the driving factors for gaining and maintaining keyword rank.
Think about it. That’s why launch services were doing so well. All a launch service did was give Amazon those conversion rates it needed to establish relevance, and allowed the listing to make it to the first page so that, if well optimized, it would continue to sell well once in front of shoppers.
However, Amazon’s primary concern isn’t how one customer finds one type of product. They are concerned with the entire shopping experience. So, they’ve optimized their site and every listing on it to be more streamlined.
This has led to some homogeneity; i.e. everything almost looks the same. That impacts the way buyers browse. Couple that with Amazon’s 50+ metrics and features that determine relevance outside of just sales, and we sellers end up with a lot less control over our success than we once had.
See, before, our Amazon listing was like a sales page. You built it well and you did well. But now, while it is still important to build a great listing, Amazon has taken a lot more of the control, and even with the best product and most optimized listing, you may underperform still (organically…hence why PPC has become so important, but that’s another article).
Writing for the Machines May Bring Back the Golden Days

However, once LLMs are implemented in relevance, we may see a return to those days. The reason is because an LLM is not going to be concerned with keyword density. It won’t have a static keyword list to reference. It won’t be guided by traditional SEO practices.
An LLM will be concerned with context over content.
This means, it won’t count the keywords, or even pay much attention to the specific word. It is going to be looking for rich descriptions of use-cases, of customer experiences, of examples of the product impacting a situation.
So…good copywriting will speak to the LLM more than all the back-end keyword strategies.
As LLMs become multi-modal it will also be able to assess and interpret imagery. It will be looking for clear and understandable pixels, products in-use, products with great background staging.
So…good photography will speak to the LLM more than all the file-name tricks out there.
In the end, A.I. isn’t going anywhere. It will remain here and, ideally, help the shopper and the seller experience thrive.
Now is the time to embrace it, learn how it impacts you as a seller, and leverage that knowledge.
*Shoutout to Kevin King and his Billion Dollar Sellers newsletter, as well as Danny McMillan and the Seller Sessions Podcast.
**All research papers and reference material are hyperlinked in the article above.
(Get the Ultimate Guide to ChatGPT for Amazon Sellers Here ==> signalytics.ai/chatgpt)